
Elasticsearch query system
Data schema
刚上手Elasticsearch,就觉得它和GraphQL有一些相似,不仅仅在于他们都是用于查询的系统,而且它们对于数据都需要提前定义好schema1(在Elasticsearch里面也叫mapping)。当然,它们本质的不同在于前者是用于做数据查询的,后者用于构建API,而API对应的处理不一定是数据的查询(或者可以理解为Elasticsearch有点像是GraphQL+数据查询系统)。
在Elasticsearch里面,定义数据的schema并不是必须的,如果没有定义好schema,那么Elasticsearch会根据内容来猜测相应的类型2,但定义好了为之后的查询也提供了便利,还能减少一些歧义。Elasticsearch内置了许多的数据类型3,从常见的text类型到复杂的object类型等等,足够应付大部分的数据了。尤其需要注意的是不同的数据类型,它们所支持的搜索方式可能也不相同(因为检索的方法就不同),比如keyword类型的field只有查询完全匹配时才能找到(它不支持评分查询,即使你使用了match或match_phrase_prefix对其进行搜索最终也会退化为term的搜索方式)。
顺带提一下,Elasticsearch是可以通过REST接口直接上传包含数据的文件的,就像文档中那样1,但需要注意的是文档中提供的数据其实是已经处理过的数据,比如它包含了下面这些内容并不是原数据的内容。所以想要拿自己的数据在Elasticsearch上面玩一玩的话,还是通过Logstash来导入数据吧。
{
"index": {
"_index": "shakespeare",
"_type": "act",
"_id": 0
}
}
Lucene syntax VS. Query DSL
我们知道Elasticsearch是基于Lucene构建起来的,所以它自然支持Lucene的搜索语法。但同时它又有自己的一套DSL,它们的区别在于,前者要更高级一些(似乎在Kibana的Discover页面就是通过前者来进行查询的),通过解析才能得到后者4(解析的结果可以通过Search Profiler来查看,参考FAQ第5条)。
下面这两种方式得到的结果是一样的,前者里面包含的正是Lucene的语法,后者是对应的DSL:
{
"query": {
"query_string": {
"query": "play_name: \"Henry IV\""
}
}
}
{
"query": {
"term": {
"play_name": "Henry IV"
}
}
}
Filtering query VS. Scoring query
Elasticsearch 中的数据可以概括的分为两类:精确值和全文。
精确值 如它们听起来那样精确。例如日期或者用户 ID,但字符串也可以表示精确值,例如用户名或邮箱地址。对于精确值来讲,
Foo和foo是不同的,2014和2014-09-15也是不同的。另一方面,全文 是指文本数据(通常以人类容易识别的语言书写),例如一个推文的内容或一封邮件的内容。
精确值很容易查询。结果是二进制的:要么匹配查询,要么不匹配。
查询全文数据要微妙的多。我们问的不只是“这个文档匹配查询吗”,而是“该文档匹配查询的程度有多大?”换句话说,该文档与给定查询的相关性如何?
上面的精确值的查询在Elasticsearch里面就叫过滤查询(filtering query),而对全文进行匹配则叫评分查询(scoring query)。简而言之,过滤查询主要是用一些确定的条件来滤掉肯定无关的数据,而评分查询则是对过滤得到的所有数据进行一个匹配程度的打分,最后再输出按照分数由高到低排序的结果。
早期的Elasticsearch是把过滤查询和评分查询分开的,而现在则是把它们放到了一起,即过滤查询得到的每条event也都有一个_score,只不过它们都是固定的值(比如都是1),而评分查询得到的_score则可能是不相同的。
由于评分查询的性能要差于过滤查询(查看后面的Elasticsearch查询内部原理),所以在DSL里面要尽量使用过滤查询。像match、match_phrase、match_phrase_prefix、multi_match、common等都是评分查询的语句。
Query DSL
Elasticsearch的DSL其实还是有点小复杂的,这里以match语句的搜索为例,简单讲一下它的格式。
首先,所有的搜索都是json格式的,并且它的最外层都是query:
{
"query": {...}
}
match是比较基本的查询方式,主要用于查询某个field匹配上了指定的规则。比如下面用于搜索play_name这个field包含Henry IV的所有events:
{
"query": {
"match": {
"play_name": "Henry IV"
}
}
}
match其实是支持很多高级的选项的,上面的语句和下面的search其实是一模一样的(operator默认就是”or”)。比如我们想找的play_name就是叫Henry IV,为了避免像Marry IV或Henry X之类也被搜索到,这里可以把operator设为”and”(即需要同时满足query中的每个单词)。
{
"query": {
"match": {
"play_name": {
"query": "Henry IV",
"operator": "or"
}
}
}
}
除了operator之外,还可以设置cutoff_frequency、zero_terms_query等选项。
以上,可以看出Elasticsearch的DSL格式就是在某一个搜索语句下(这里是match)首先放field的名称,field名称还可以嵌套一个key/value的字典,里面放对应的搜索语句的选项。
Elasticsearch查询内部原理
根据《Elasticsearch权威指南》,以term关键词做过滤为例,它的执行顺序为:
查找匹配文档.
term查询在倒排索引中查找XHDK-A-1293-#fJ3然后获取包含该 term 的所有文档。本例中,只有文档 1 满足我们要求。创建 bitset.
过滤器会创建一个 bitset (一个包含 0 和 1 的数组),它描述了哪个文档会包含该 term 。匹配文档的标志位是 1 。本例中,bitset 的值为
[1,0,0,0]。在内部,它表示成一个 “roaring bitmap”,可以同时对稀疏或密集的集合进行高效编码。迭代 bitset(s)
一旦为每个查询生成了 bitsets ,Elasticsearch 就会循环迭代 bitsets 从而找到满足所有过滤条件的匹配文档的集合。执行顺序是启发式的,但一般来说先迭代稀疏的 bitset (因为它可以排除掉大量的文档)。
增量使用计数.
Elasticsearch 能够缓存非评分查询从而获取更快的访问,但是它也会不太聪明地缓存一些使用极少的东西。非评分计算因为倒排索引已经足够快了,所以我们只想缓存那些我们 知道 在将来会被再次使用的查询,以避免资源的浪费。
为了实现以上设想,Elasticsearch 会为每个索引跟踪保留查询使用的历史状态。如果查询在最近的 256 次查询中会被用到,那么它就会被缓存到内存中。当 bitset 被缓存后,缓存会在那些低于 10,000 个文档(或少于 3% 的总索引数)的段(segment)中被忽略。这些小的段即将会消失,所以为它们分配缓存是一种浪费。
以上,就知道为啥在Elasticsearch中做第一次搜索往往比较耗时,因为人家是有缓存的。另外,由于它的搜索迭代顺序是启发式的,因此我们在搜索里面的query的各个条件的顺序并不重要,而作为对比,Splunk的SPL的各个pipeline的顺序则很关键,比如把能过滤掉大量数据的pipeline放在前面执行可以大大地提高搜索效率。最后,减少评分查询(scoring queries)也能够提高搜索的速度,因为评分查询不会被缓存,且会有额外的计算工作。
FAQ###
-
如何只搜索指定的index下的events?
通过往不同的endpoint发送请求可以达到搜索不同的index的目的。比如:
-
/_search在所有的索引中搜索所有的类型
-
/gb/_search在
gb索引中搜索所有的类型 -
/gb,us/_search在
gb和us索引中搜索所有的文档 -
/g*,u*/_search在任何以
g或者u开头的索引中搜索所有的类型 -
/gb/user/_search在
gb索引中搜索user类型 -
/gb,us/user,tweet/_search在
gb和us索引中搜索user和tweet类型 -
/_all/user,tweet/_search在所有的索引中搜索
user和tweet类型
-
-
term和match、match_phrase的区别?简单说,
term不会对要搜索的字符串进行任何处理,只会返回完全匹配的events,而match_phrase则会对搜索的字符串先进行分析,比如某个单词大小写都能被匹配到(参考:https://stackoverflow.com/questions/26001002/elastic-search-difference-between-term-match-phrase-and-query-string)。而match则更加宽松了,它允许搜索的字符串中分词后的顺序也有所变化,甚至只出现其中某些单词(operator设为”or”),比如”He is hero”会把包含”he is”的也搜索出来。 -
搜索的结果和预期完全不同,该如何进行“debug”?
正好《Elasticsearch权威指南》中就有这样一个例子,简单的说,Elasticsearch提供了许多endpoint用于“debug”,比如
GET /shakespeare/_analyze就会返回某个field下字符串经过分析器分析的结果,然后你会发现有可能是定义的schema中这个field在做索引时分词出了问题。 -
通过Elasticsearch的REST做搜索时如何查看返回的所有结果(默认只返回前10个结果)?
通过在搜索请求后面添加
size和from参数可以返回更多的结果。比如GET /_search?size=20&from=40会返回第41到第60个共20条events。但这里要注意的是,搜索需要返回的结果越靠后,搜索的耗时是会越多的,这是因为搜索的结果是排序后输出的,而返回的结果越靠后则需要检索出来并排序的events就越多,具体可以参考《Elasticsearch权威指南》。 -
以下两个搜索得到的结果是一样的,它们有区别么?
{ "query": { "term": { "price": 20 } } }{ "query": { "constant_score": { "filter": { "term": { "price": 20 } } } } }使用Kibana自带的Search Profiler可以大概看到Elasticsearch是怎样解析这两个搜索的,并且可以比较一下它们的耗时:
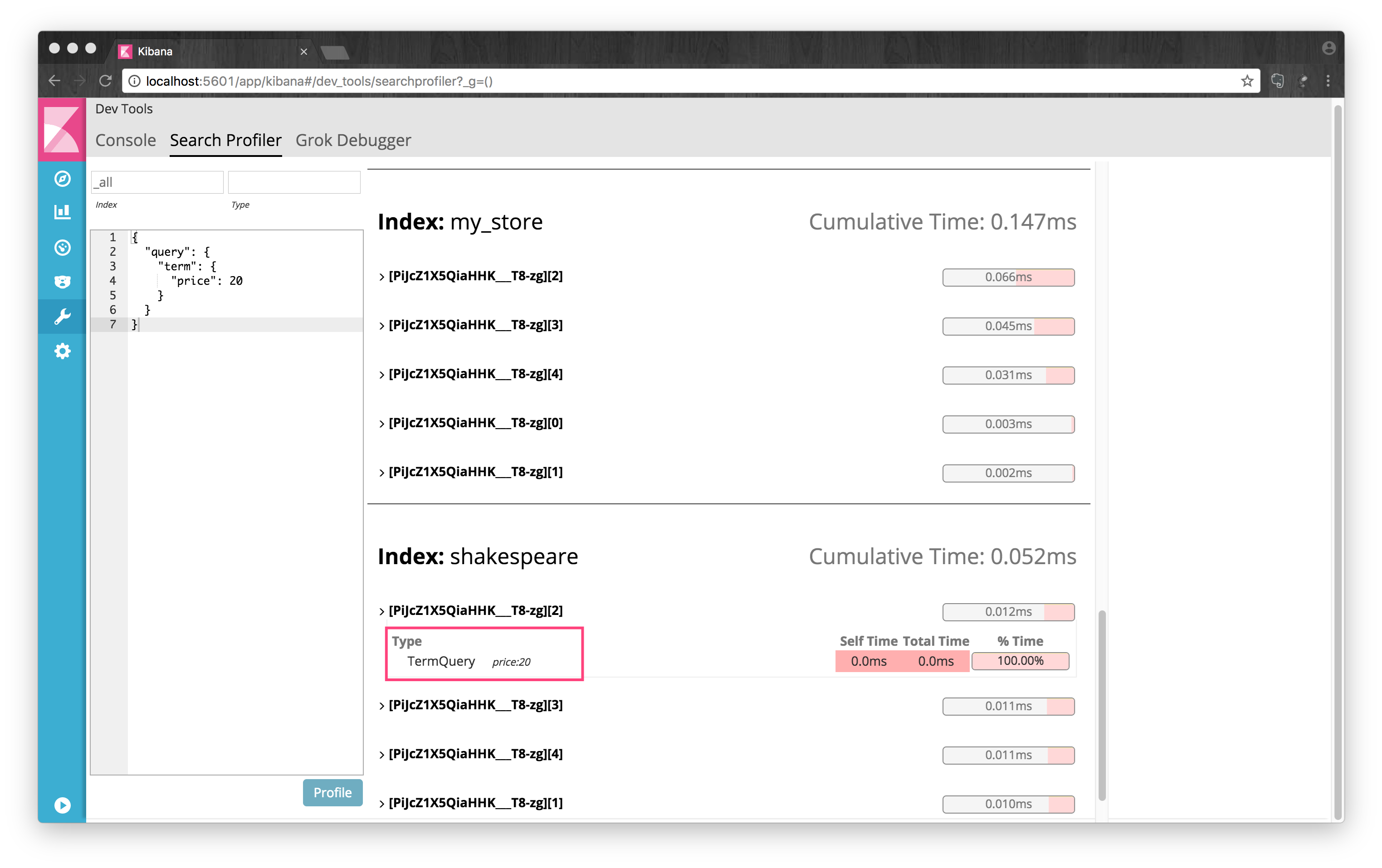
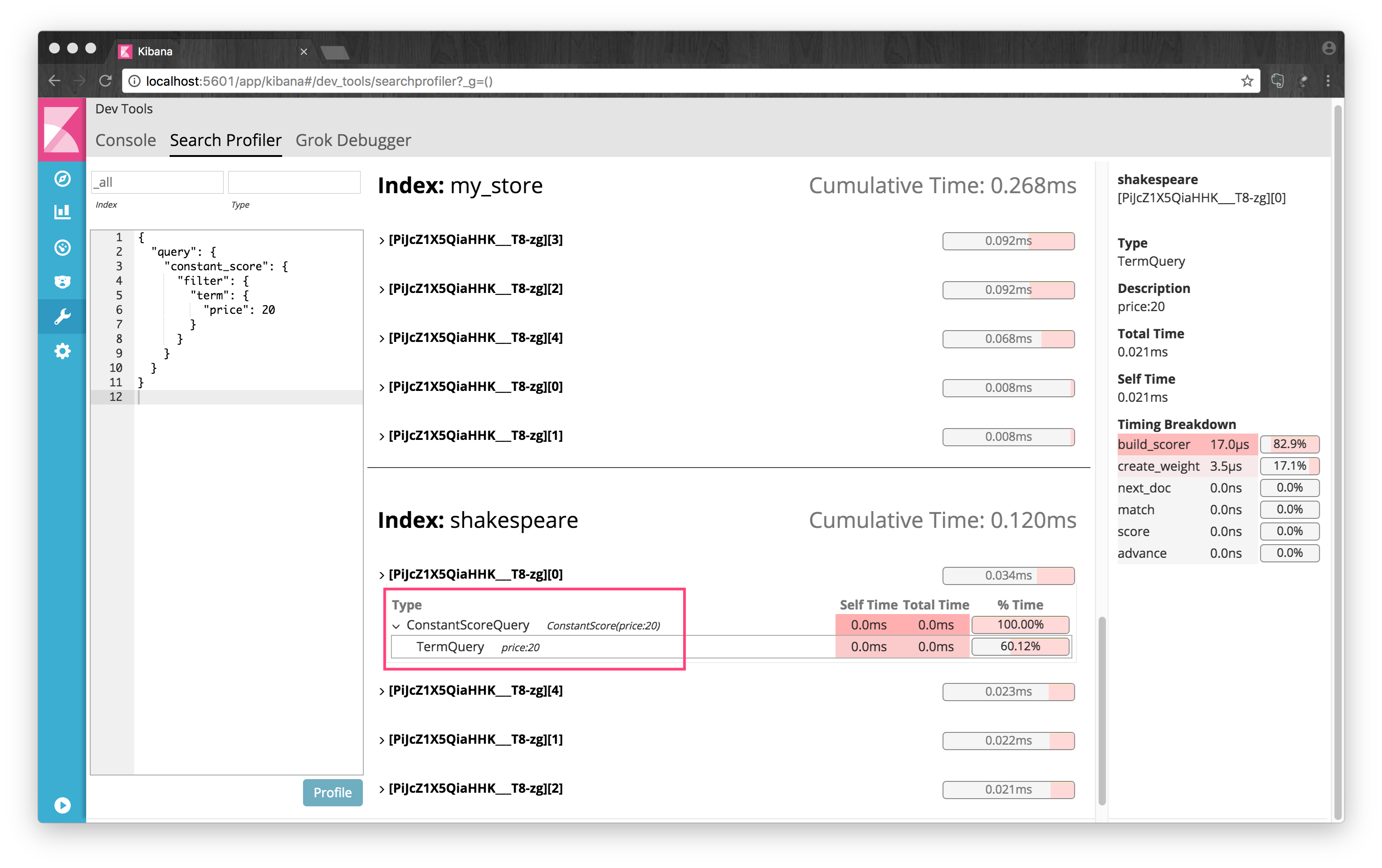
可以看出它们解析出来是略微不同的,而且耗时也是前者要少一些。
-
https://www.elastic.co/guide/en/kibana/current/tutorial-load-dataset.html ↩ ↩2
-
https://www.elastic.co/guide/cn/elasticsearch/guide/current/mapping-intro.html ↩
-
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html ↩
-
https://stackoverflow.com/questions/37689935/whats-the-difference-between-query-string-and-multi-match ↩
Comments