About convolutional neural network
其实关于CNN很早之前就已经知道了它大概是什么原理,以及它为何比人为提取的特征用来训练得到的效果更好。可以说CNN几乎终结了计算机视觉领域靠人为提取特征的时代(也就是我刚开始学习进入这领域的时候😂)。
但这里我想从头梳理一遍,以普通的神经网络为切入点,换个角度研究下CNN。
-
总体而言,CNN和普通的神经网络的区别:
First of all, the layers are organised in 3 dimensions: width, height and depth. Further, the neurons in one layer do not connect to all the neurons in the next layer but only to a small region of it. Lastly, the final output will be reduced to a single vector of probability scores, organized along the depth dimension.
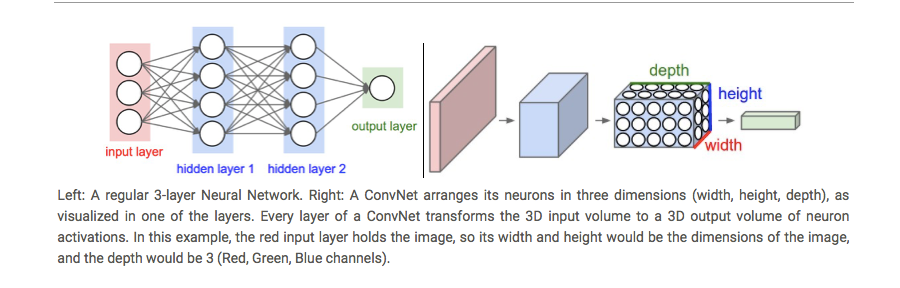
-
CNN中一共有这么几种layer:
- INPUT [32x32x3] will hold the raw pixel values of the image, in this case an image of width 32, height 32, and with three color channels R,G,B.
- CONV layer will compute the output of neurons that are connected to local regions in the input, each computing a dot product between their weights and a small region they are connected to in the input volume. This may result in volume such as [32x32x12] if we decided to use 12 filters.
- RELU layer will apply an elementwise activation function, such as the max(0,x) thresholding at zero. This leaves the size of the volume unchanged ([32x32x12]).
- POOL layer will perform a downsampling operation along the spatial dimensions (width, height), resulting in volume such as [16x16x12].
- FC (i.e. fully-connected) layer will compute the class scores, resulting in volume of size [1x1x10], where each of the 10 numbers correspond to a class score, such as among the 10 categories of CIFAR-10. As with ordinary Neural Networks and as the name implies, each neuron in this layer will be connected to all the numbers in the previous volume.
INPUT就不说了,CONV是卷积层,也是CNN的核心,卷积层最大的特点(相比于一般的NN)是它只关注输入的局部信息;RELU层的作用应该和普通的NN差不多:注入一些非线性的因素;POOL是池化层,作用类似于降采样,降采样后再输入到下一层卷积层,那么更全局的信息就被关注到了,可以有效的降低overfitting(试想下如果只给你看树叶的纹路,鬼能看得出这是什么树)和提高robust(即使图像有一些平移或旋转,降采样后可能是一样的,所以没有太大影响);FC是全连接层,可以理解为就是把之前各种卷积、池化等操作之后的输出展开为一维的向量,再输入到了一个普通的神经网络中(普通的NN中每一层都是全连接的)。
-
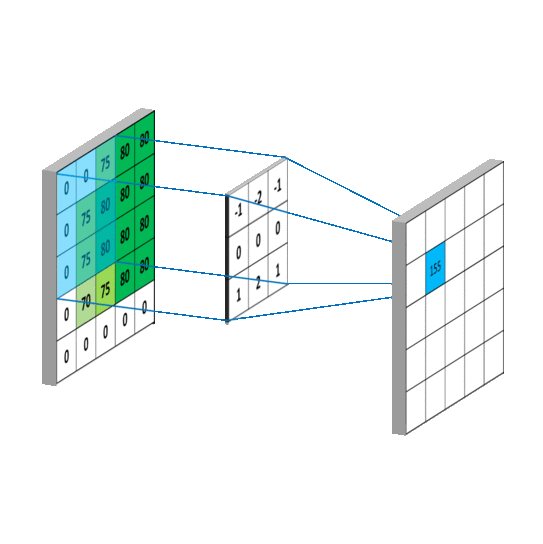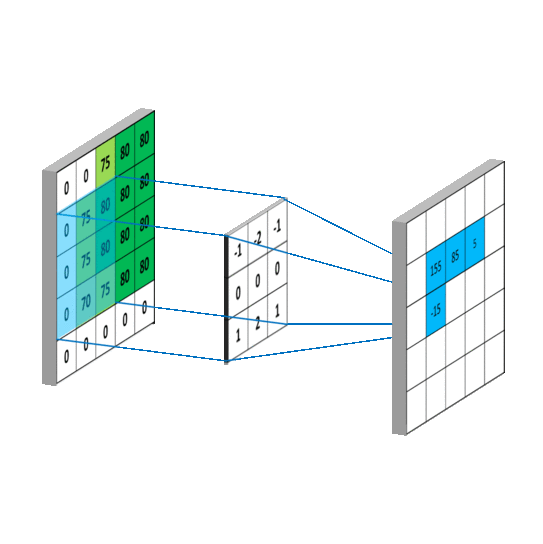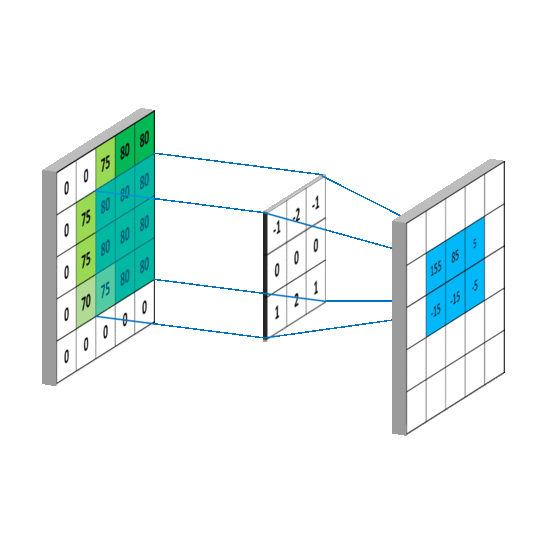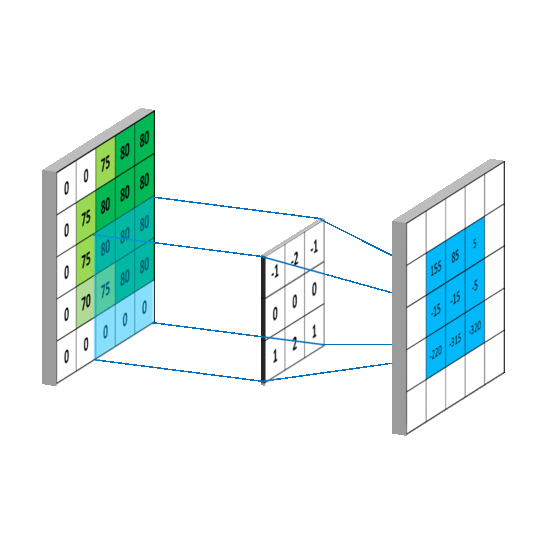
关于卷积:卷积其实就是加权叠加,在图像处理中通常会选用一个较小的矩阵模板(也叫描述子或卷积核,比如一个3x3的矩阵)来对图像中的每一个像素和其周围部分像素进行加权叠加计算,从而得到一个全新的图像(对于图像边缘的像素,一般会采取镜像操作来填充一些图像外的点来计算,以保证卷积过后的图像尺寸不变,比如要在图像
[5,0]处和3x3的矩阵进行卷积,那么我们会用[5,1]处的图像像素来填充到[5,-1]的位置,然后就可以进行卷积啦)。图像卷积在图像处理中的应用非常广泛,比如图像的去噪、锐化、模糊化、边缘检测等等,这些操作其实都是在图像上进行卷积,所不同的是它们使用的卷积核不同罢了。